本文主要介绍自然语言处理中的常见任务有哪些,参考材料为李宏毅教授的课程
NLP任务中的两大分类
假设将NLP看作一个黑匣子,把任务按照黑匣子的能力分类,可以分成两大类:
- 输入一段文字,输出一段文字
- 输入一段文字,输出分类结果
Input:文字
Output:文字|类别
NLP的黑匣子中是各种各样的NLP模型,各自处理着不同场景下的不同任务:
- 对于模型输入来说,文字的输入也可能有多种形式
- 对于模型输出,输出的类别既可以是对整个sequence的分类标签,也可以是针对句子中某一个组成元素的分类标签
将NLP任务基于模型的输入输出分类
Input: One Sequence| Multiple Sequences
Output: One Class| Class for each token| Copy from Input| …
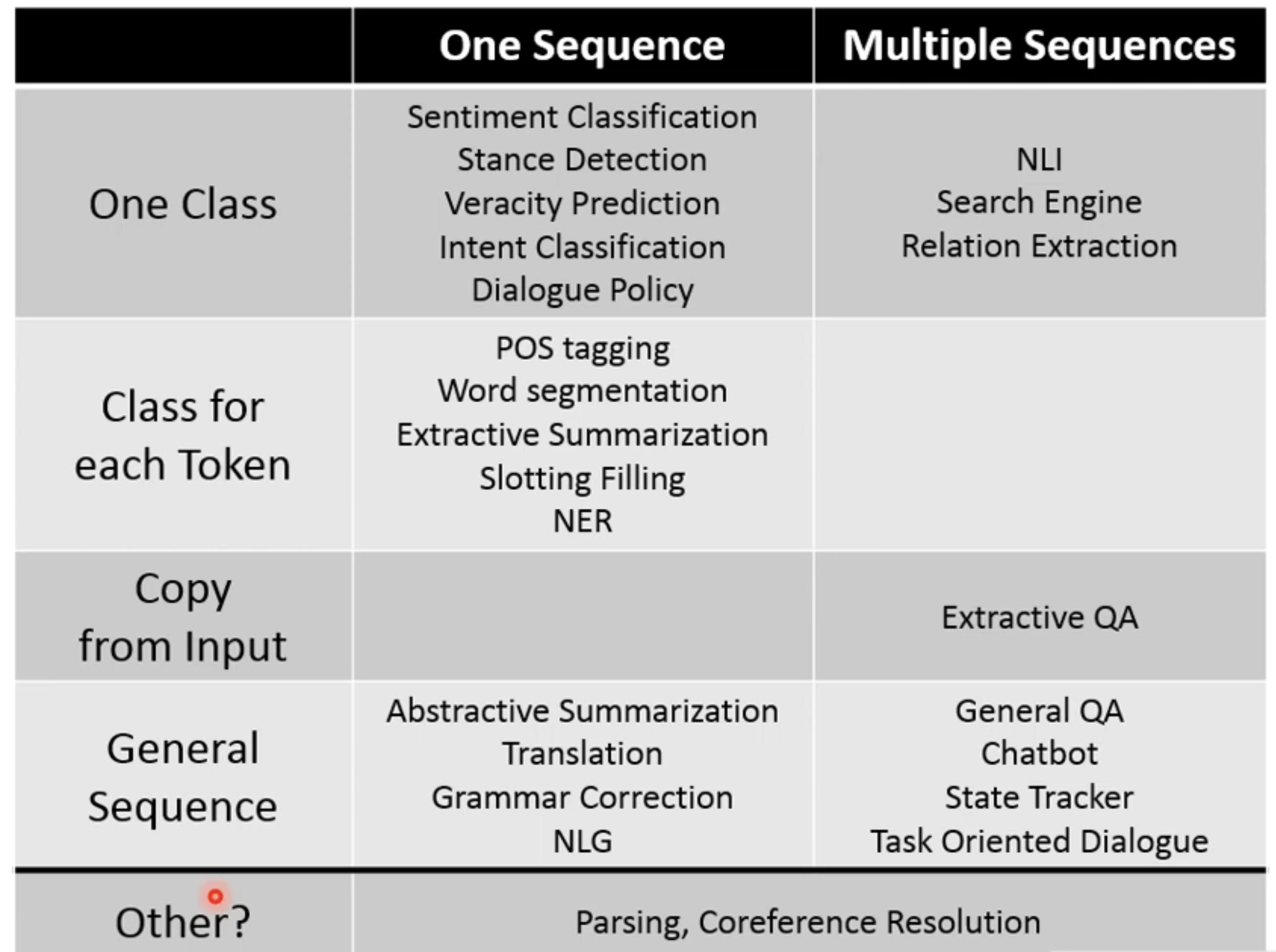
1. POS part of Speech Tagging
给所有的词标注词性,输入为一段文本(sequence),输出为此文本中所有单词及对应的词性(class for each token)
2. Word Segmentation
对于中文来说,有时候是需要的,因为中文不像英文有空格这个天然的分词符号,分词有时候是有歧义的。但是Bert模型的出现,说明分词可能不太需要(Bert将所有字单独拆为一个个token,而不是用词当token)
3. Parsing
输入:一个句子;输出:一个树状结构
分类:Constituency Parsing|Dependency Parsing
Parsing的结果通常会作为downstream任务的额外feature input
4. Coreference Resolution 指代消解
和parsing一样,通常作为downstream任务的额外feature input
5. Summarization 生成摘要
类型1: Extractive Summarization,在文章中找到合适的句子,拼接成summary。Input:Sequence;Output:class for token(sentence)
类型2:Abstractive summarization,seq2seq任务,input为长句子,output为短句子
6. Machine Translation
Unsupervised machine translation is a critical research direction.因为世界上有7000+语言,要收集不同语言之间的映射,作为模型的有监督训练是不实际的。
7. Grammar Error Correction
也是一个seq2seq任务。当然,也可以用token classifier来做,output就是每一个token的类别:[不用改,要改,要在后面增加内容]
8. sentiment classification
输入一段文字,判断情感是偏正面还是负面
input:sequence;output:class;
常用场景:商品、电影等的评价。
9. Stance Detection
立场鉴别:support、deny、Querying、Commenting(SDQC)
input:2 sequences;output:class;
10. Veracity Prediction
判断信息的真伪
input:several sequences;output:class;
11. Natural Language Inference(NLI)
premise:一个前提
Hypothesis:假设
让Model经过一个premise,判断hypnosis成不成立,model输出通常为三类:contradiction、entailment(蕴含)、neutral(中性)
12. Search Engine
Bert据说已经用在Google搜索里面了。
13. Question Answering
传统的QA(非end2end模型)处理流程:
1. Question processing:对问题文本进行分词、命名实体标注、关系提取、指代消解等处理;
2. Document and passage retrieval:从数据库中基于标签、index等信息通过TF-IDF等算法找到相关的文章和段落
3. 经过Answer type detection的过滤,得到最终的结果即使是end2end的QA应用,目前也还没有做到让模型理解input sequence然后生成output answer sequence,而是在input question,document中提取出answer,即document中已经包含了answer。
14. Dialogue 对话系统
14.1 Chatting 闲聊
input: several sequences;
output: sequence;
同时,我们希望chatbot不仅仅是基于过去的对话生成新的对话,我们可能还会希望面对不同的用户,chatbot能有不同人格的回复,会有一些同理心等等。
14.2 Task-oriented 任务式对话系统
通常使用在订票、人工客服等场景下。模型需要获得完成任务的关键信息,然后基于获得的关键信息进行对话响应和任务执行。
15. 知识图谱
它就是一种图结构,其中的节点是实体,节点之间的有向边是关系。现在有一个研究方法是输入大量的文档中让机器自己输出知识图谱。解决这个问题主要有两步:1. 抽取实体 2.抽取关系
额外延伸——自然语言处理的难点在哪里?
- 自然语言千变万化,没有固定格式,同样的意思可以使用多种句势来表达
- 不断有新的词汇出现,机器需要不断的学习
- 在不同的上下文语境下,同一句话表达的意思可能不一样