idea:
- 将所有word都project到一个high dimensional space(但是这个“high”也远比1-of-N的维度低的多)上
- Embedding中的每一个dimension都有自己的含义
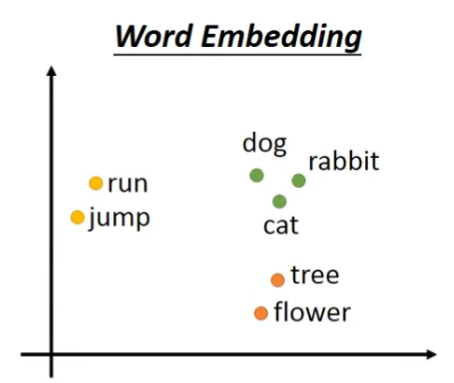
Word Embedding是一种无监督式学习,只需要让模型阅读大量的文本资料,模型就能学习怎么将如何用vector表示所有单词学习出来。
那怎么找到这样的function去训练模型 exploit the context?
有以下两种思路:(1)count based;(2)prediction based;
Count Based

让Word w_i和w_j的向量乘积能够近似于w_i和w_j共同出现的document数量。
Prediction Based
given a word, predict 下一个word是什么
input: 词汇的 1-of-N encoding
output: 概率分布vector,dim=N
完成训练后,模型是中间的hidden layer-z。因为不同的w_i作为input放进模型的时候,对应的z_i不同,可以用z_i表示w_i.
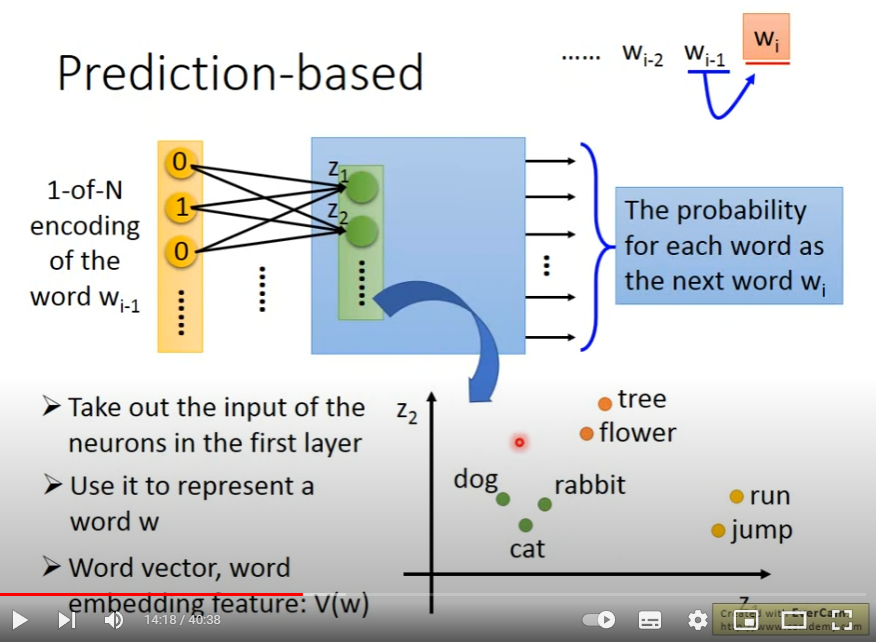
prediction-based为什么可以学习到context信息?
下面的例子(抛开政治含义)是说:如果training data中,两个人名后面跟着的word一致,那么模型需要让两个人名作为input的时候,输出的probability distribution vector应该要差不多,才能保证预测的下一个词是一样的。
那么,为了实现这一点,中间的hidden layer就会倾向于将两个人名project到一个比较接近的空间,这样就能实现context的捕捉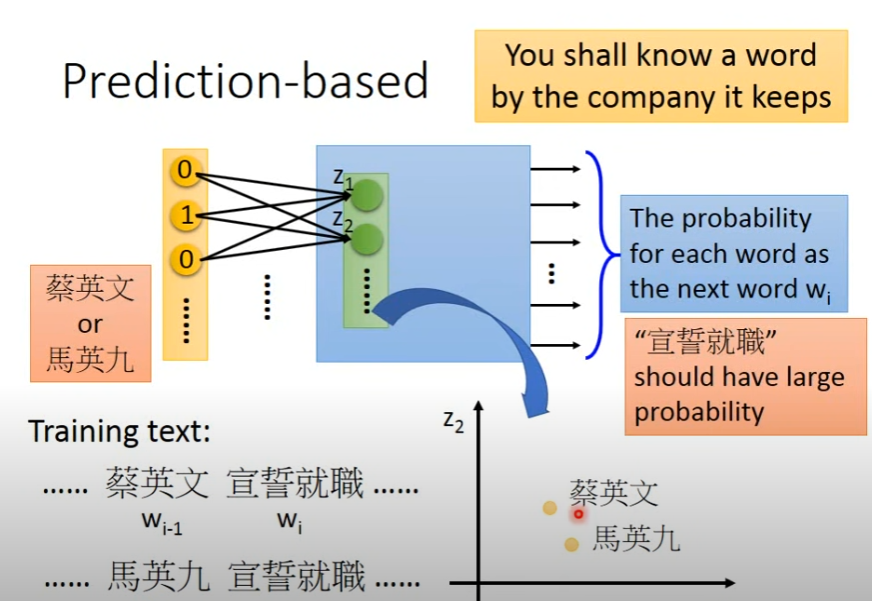
given 2 words, predict 下一个词是什么
Prediction-based-Sharing Parameters
idea:只用一个词去预测下一个词可能不可靠,应该用多个词一起去预测下一个词
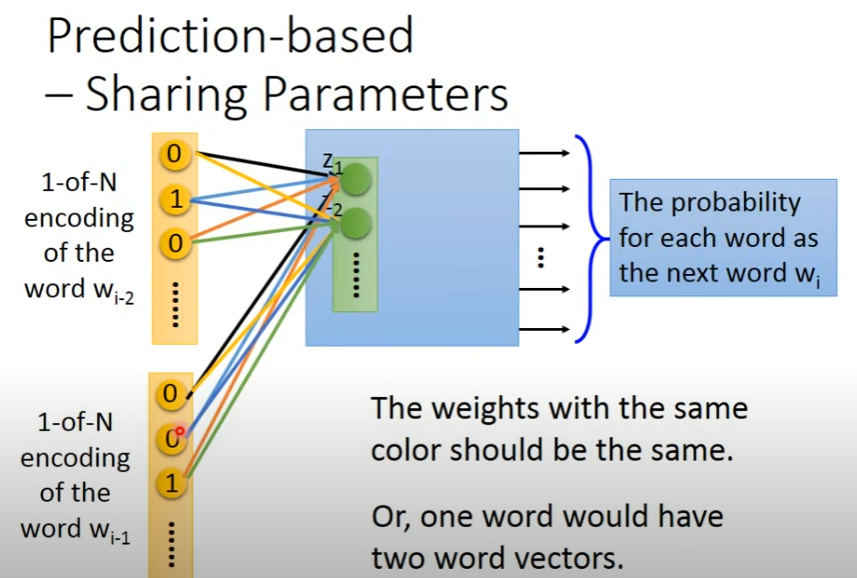
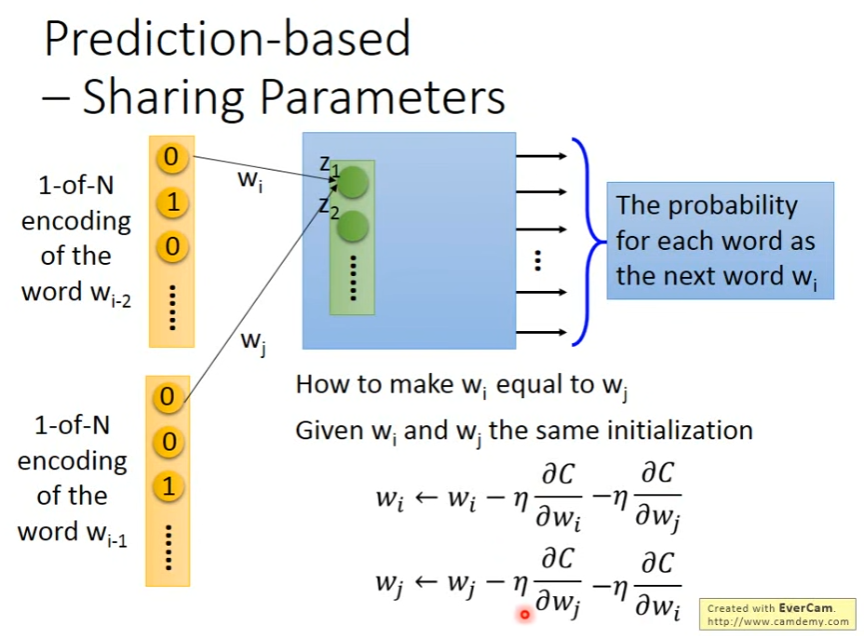
- 在上图中,为了保证w_i, w_j保持一致(共享权重),需要:
- 初始化一致
- 在更新参数w_i时,不仅更新w_i本身的偏微分,还会更新w_j的偏微分,更新w_j时同理
- 在上图中,为了保证w_i, w_j保持一致(共享权重),需要:
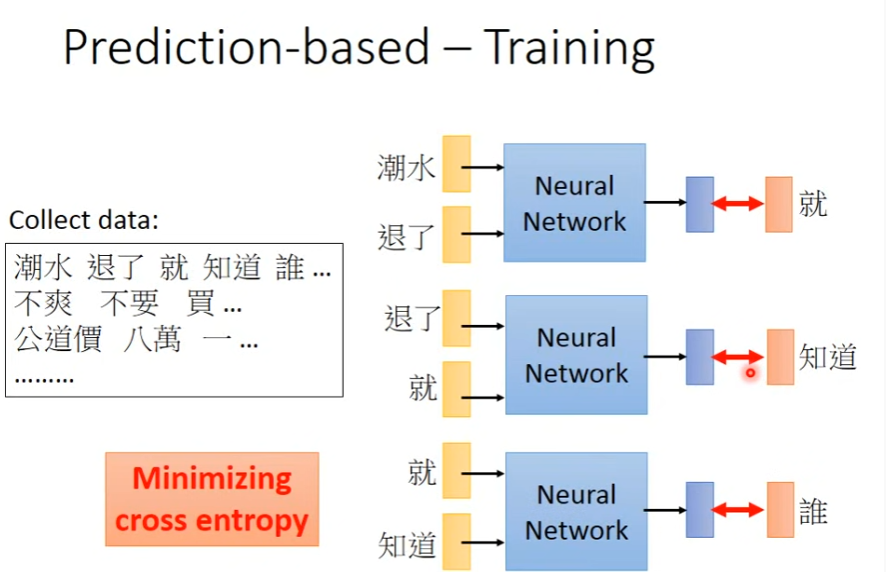
Prediction Based Training methods
1. Basic
Input:两个相邻词的1-of-n encoding
Output: 概率分布vector,dim=N
Loss:概率分布vector与下一个词的1-of-n encoding的cross entrophy
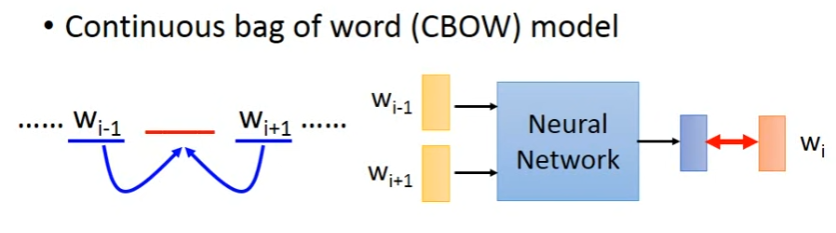
2. CBOW-Continuous bag of word model
思路:用w_i-1, w_i+1去预测w_i
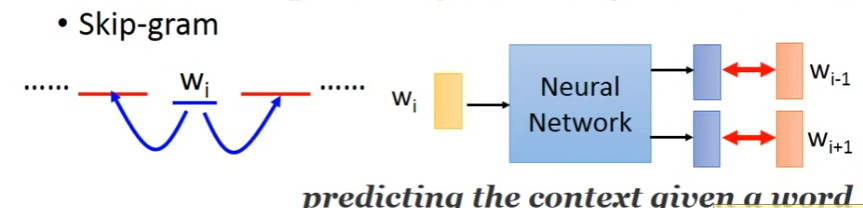
3. Skip-gram
思路:给一个词w_i,去预测上下文w_i-1, w_i+1
Word Embedding一些有趣的特性

左图:国家和其首都的vector之间的联系很相像,所以可以做有趣的计算,如:(China-Japan)+ tokyo=Beijing,或者像下图一样,计算Berlin是哪个国家的首都

右图:一个单词的不同时态的vector构成的三角形很相似